|
<< Click to Display Table of Contents >> Администрирование (Windows) > Общесистемные настройки > Настройка полнотекстового поиска Индексирование отсканированных документов
|
|
В системе есть документы без текстового слоя – скан-копии. Зачастую их нужно найти по фрагменту текста. Для этого необходимо настроить индексирование отсканированных документов, чтобы на них распространялись возможности полнотекстового поиска также, как на документы с текстовым слоем.
За индексирование отсканированных документов отвечает фоновый процесс «Документооборот. Индексация скан-копий для полнотекстового поиска». Он запускается по расписанию, по умолчанию каждые 5 минут.
Чтобы включить или выключить фоновый процесс, а также настроить расписание его запуска, используйте список «Фоновые процессы». Подробнее см. раздел «Настройка и мониторинг выполнения фоновых процессов».
Принцип работы фонового процесса
1.Фоновый процесс отбирает созданные или измененные документы, которые соответствуют критериям:
•имеют расширения BMP, GIF, JPEG, JPG, PNG, TIF, TIFF, PDF;
•занесены в систему за период с предыдущего запуска;
•не зашифрованы;
•размер каждого файла не превышает 75 МБ.
2.По каждому из документов фоновый процесс создает элемент очереди и запускает асинхронные обработчики. Каждый документ – один асинхронный обработчик. Чтобы ускорить процесс индексирования, несколько обработчиков запускаются одновременно. Их количество администратор может регулировать в таблице Sungero_Docflow_Params в параметре IndexDocumentsQueueItemsLimit. Администратор может настраивать этот и другие параметры в зависимости от возможностей аппаратного обеспечения компании.
Примечание. Фоновый процесс работает, если приобретена лицензия на модуль Intelligence, настроено индексирование документов с помощью Elasticsearch, а также установлено подключение к сервисам Ario в справочнике «Настройки интеллектуальной обработки».
Принцип работы асинхронного обработчика
1.Асинхронный обработчик отправляет в сервисы Directum Ario запрос на извлечение текстового слоя.
2.После получения извлеченного текстового слоя асинхронный обработчик отправляет его на индексирование в поисковую систему Elasticsearch. В результате обработки индексы документов обновляются и документы становятся доступны для полнотекстового поиска.
3.После завершения всех операций асинхронный обработчик удаляет элемент очереди.
Чтобы индексирование отсканированных документов происходило корректно:
1.В базе данных откройте таблицу Sungero_Docflow_Params.
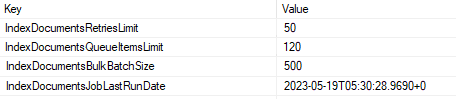
2.В таблице заполните параметры:
•IndexDocumentsRetriesLimit – количество повторов запуска. Значение по умолчанию – 50;
•IndexDocumentsQueueItemsLimit – количество одновременно запускаемых асинхронных обработчиков. Значение по умолчанию – 120;
•IndexDocumentsBulkBatchSize – количество документов, обрабатываемых за один раз при массовом индексировании исторических документов. Значение по умолчанию – 500;
•IndexDocumentsJobLastRunDate – дата последнего запуска фонового процесса. Параметр заполняется автоматически.
Для определения оптимальных значений воспользуйтесь рекомендацией:
1.Запустите фоновый процесс с настройками по умолчанию.
2.Проанализируйте информацию в лог-файлах. Сравните время завершения работы асинхронных обработчиков и время следующего запуска фонового процесса. Затем при необходимости скорректируйте настройки:
•если на момент нового запуска фонового процесса асинхронные обработчики еще не завершили работу, то уменьшите значение в параметре IndexDocumentsQueueItemsLimit;
•если между окончанием работы асинхронных обработчиков и запуском нового фонового процесса прошло значительное количество времени, то увеличьте значение.
Если время примерно совпадает, оставьте значения по умолчанию.
| © Компания Directum, 2025 |