|
<< Click to Display Table of Contents >> Интеллектуальные возможности > Интеллектуальная обработка документов > Сопровождение интеллектуальной обработки документов Обучение и дообучение виртуальных помощников |
|
Обучение и дообучение виртуальных помощников
|
<< Click to Display Table of Contents >> Интеллектуальные возможности > Интеллектуальная обработка документов > Сопровождение интеллектуальной обработки документов Обучение и дообучение виртуальных помощников |
|
Для руководителей можно создать виртуального помощника. Он может автоматически:
•создать проект резолюции и добавить его во вложения задачи на рассмотрение документа. В таком случае руководителю приходит задание на рассмотрение документа с уже готовым проектом резолюции;
•сформировать проект подчиненного поручения и определить его исполнителя.
Для того чтобы достоверно определять исполнителя, виртуальные помощники регулярно обучаются:
•на подчиненных поручениях, созданных руководителями;
•на документах для исполнения;
•на поручениях, выданных в ходе рассмотрения.
Обучение производится с помощью фоновых процессов:
•«Интеллектуальные функции. Подготовка данных для обучения виртуальных ассистентов»;
•«Интеллектуальные функции. Обучение виртуальных ассистентов».
Виртуальных помощников можно обучить также на исторических данных.
Алгоритм обучения виртуального помощника
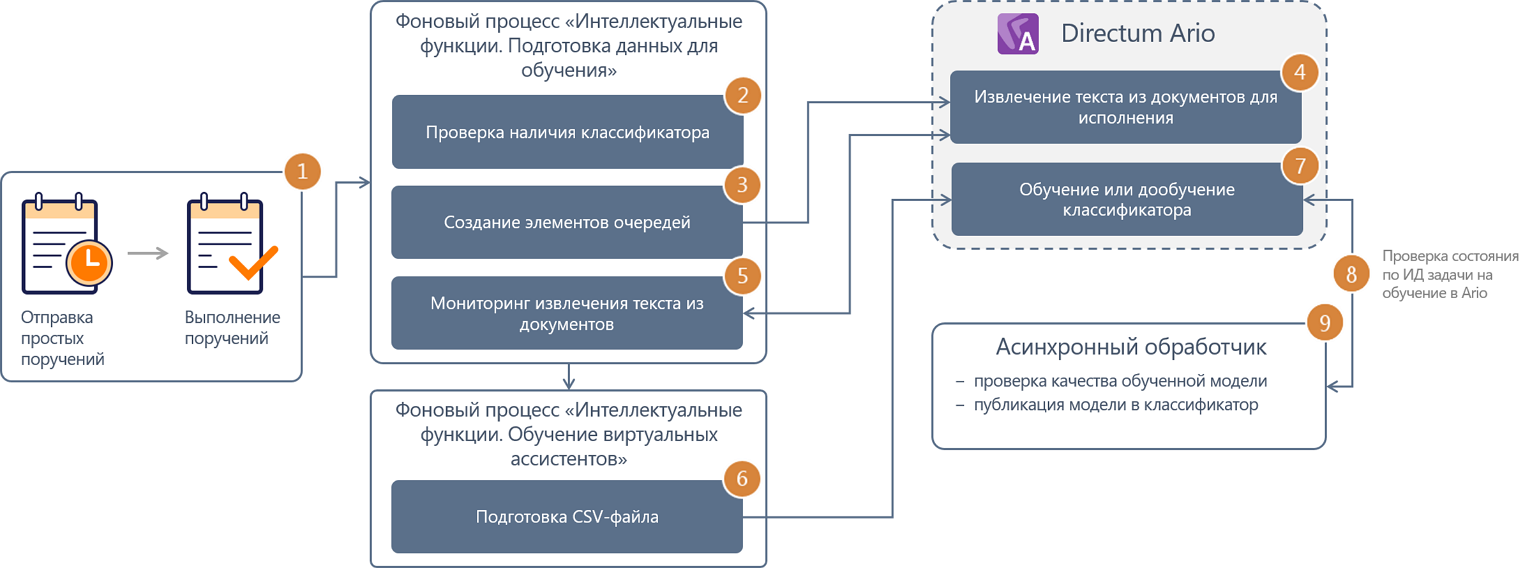
1.Накопление данных для обучения.
Для обучения виртуального помощника отбираются стартованные задания на исполнение поручений, удовлетворяющие условиям:
•поручение выдано руководителем, для которого настроен виртуальный помощник;
•тип выданного поручения должен быть простым;
•во вложении есть незашифрованный документ для исполнения.
2.Подготовка данных для обучения.
Фоновый процесс «Интеллектуальные возможности. Подготовка данных для обучения виртуального помощника» запускается каждые 15 минут и проверяет наличие данных для обучения. Если с момента предыдущего запуска фонового процесса появились новые отобранные поручения, фоновый процесс проверяет наличие классификатора по исполнителям у виртуального ассистента:
•если его нет, фоновый процесс создает новый классификатор по исполнителям, который будет обучаться на накопленных данных. Информация о созданном классификаторе отображается в карточке виртуального ассистента на вкладке «Дополнительно» в табличной части «Параметры классификаторов Ario»;
•если он есть, классификатор по исполнителям будет дообучаться на накопленных данных.
3.Создание элементов очередей.
Затем фоновый процесс создает элементы очередей:
•на извлечение текста. В очередь попадают документы для исполнения по отобранным поручениям. Для каждого документа создается один элемент очереди. Если по документу создано несколько поручений, в очереди записи не дублируются;
•на обучение классификаторов по исполнителям. Для каждого отобранного поручения создается свой элемент очереди, в котором содержится информация: ИД классификатора по исполнителям, ИД поручения и ИД элемента очереди на извлечение текста.
В очередь на обучение не добавляются одинаковые поручения, например, если руководитель создал несколько поручений по одному документу для разных исполнителей.
4.Отправка документов на извлечение текста в сервисы Directum Ario.
В очереди на извлечение текста документы сортируются по дате их добавления. На извлечение текста по умолчанию отбираются 20 документов, которые были добавлены в нее последними. Затем они отправляются на обработку в сервисы Directum Ario.
Количество документов из очереди, которые отправляются на извлечение текста за раз, можно регулировать в таблице базы данных Sungero_Docflow_Params в параметре TextExtractionTasksMaxCount в зависимости от аппаратно-программного обеспечения сервера.
5.Мониторинг извлечения текста из документов для исполнения.
При повторных запусках фоновый процесс «Интеллектуальные функции. Подготовка данных для обучения» проверяет в сервисах Directum Ario статус задач на извлечение текста и для:
•документов, из которых успешно извлекся текст, меняет статус элемента очереди и сохраняет в его запись извлеченный текст;
•документов, у которых сервисы Directum Ario не успели извлечь текст, не меняет статус элемента очереди;
•документов, при обработке которых возникла ошибка, меняет статус элемента очереди. В дальнейшем этот документ не участвует в обучении.
Также при повторном запуске фоновый процесс проверяет новые данные для обучения, и повторяет свои действия: подготавливает эти данные для обучения и отправляет документы на извлечение текста.
6.Подготовка CSV-файла для обучения.
Фоновый процесс «Интеллектуальные функции. Обучение виртуальных ассистентов» запускается раз в сутки. Он формирует CSV-файл для каждого классификатора по исполнителям, указанного в карточках виртуальных помощников.
Если классификатор обучается впервые и в записи виртуального помощника на вкладке «Дополнительно» в табличной части «Параметры классификаторов Ario» для него не заполнен ИД модели, CSV-файл формируется при условиях:
•руководитель отправил поручения двум и более исполнителям;
•для каждого исполнителя сервисы Directum Ario обработали более 10 документов.
Если классификатор дообучается, CSV-файл формируется при условии, что сервисы Directum Ario обработали более 10 документов по всем исполнителям.
Если условия не выполняются, CSV-файл не создается и классификатор не обучается. Накопление данных для обучения продолжается.
В CSV-файле фиксируются извлеченный текст документов и ИД исполнителей поручений.
Для равномерного распределения нагрузки на сервисы Directum Ario и сервис асинхронных событий (Worker) или общий сервис (GenericService) размер итогового CSV-файла не превышает заданный лимит, по умолчанию 100 МБ.
СОВЕТ. В зависимости от аппаратно-программного обеспечения сервера и объема обрабатываемых документов лимит можно регулировать в таблице базы данных Sungero_Docflow_Params в параметре CsvTrainingDatasetLimit.
7.Отправка запроса на обучение классификатора в сервисы Directum Ario.
Фоновый процесс «Интеллектуальные функции. Обучение виртуальных ассистентов» отправляет запрос на обучение классификатора в сервисы Directum Ario, которые ставят набор полученных данных в очередь и передают в систему идентификатор задачи на обучение.
8.Мониторинг обучения классификатора.
Фоновый процесс запускает асинхронный обработчик, который по идентификатору задачи на обучение раз в 5 минут запрашивает у сервисов Directum Ario статус обучения.
Когда обучение завершено, асинхронный обработчик добавляет ИД обученной модели классификации в карточке виртуального ассистента на вкладке «Дополнительно» в табличную часть «Параметры классификаторов Ario».
9.Проверка качества обученной модели классификации и ее публикация.
Асинхронный обработчик сравнивает количество документов для исполнения, на которых обучалась модель, с эталонным значением. Эталонное значение задается в таблице базы данных Sungero_Docflow_Params в параметре MinTrainingSetSizeToPublishClassifierModel.
При обучении используются не все документы из выборки: 10% от количества документов используется для внутреннего тестирования классификатора. Поэтому, если 90% от количества документов:
•больше или равно эталонному, то в классификатор публикуется модель. Информация об этом отображается в карточке виртуального ассистента. После этого, если руководитель получает задание на исполнение поручения, во вложении автоматически добавляется проект подчиненного поручения;
•меньше эталонного, модель не публикуется, ее обучение продолжается при следующем запуске фонового процесса. Информация об этом отображается в карточке виртуального ассистента.
Изменение минимального порога классификации
После дообучения классификатора и публикации дополненной модели проекты подчиненных поручений могут не создаваться. Это может быть связано с тем, что сервисы Directum Ario недостаточно точно определяют возможных исполнителей подчиненного поручения: вероятность их классификации невысокая, чтобы считаться достоверной.
Минимальная вероятность классификации задается в записи справочника виртуального помощника на вкладке «Дополнительно» в табличной части «Параметры классификаторов Ario» в столбце Нижняя граница доверия классификации:
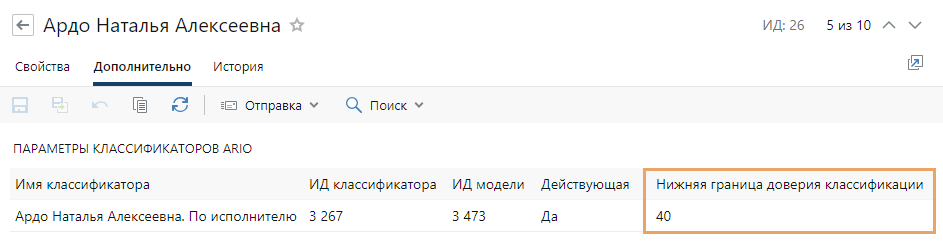
Если подобная ситуация повторяется часто, рекомендуется снизить это значение.
После изменения оргструктуры компании, например руководитель с настроенным виртуальным помощником перевелся в другой отдел, основные исполнители поручений от руководителя могут поменяться. Тогда в созданных проектах подчиненных поручений исполнители будут определяться неправильно, так как модель классификации обучена на старых данных.
На дообучение модели классификации потребуется время, но это не гарантирует, что старые данные не будут влиять на результат классификации. Поэтому рекомендуется сбросить данные обученного классификатора. Для этого в записи справочника виртуального помощника нажмите на кнопку Сброс результатов обучения:
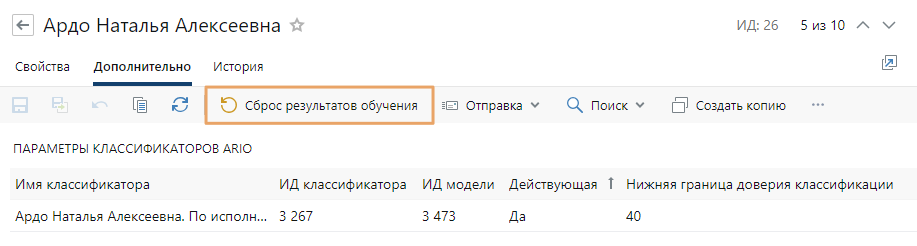
Примечание. Кнопка Сброс результатов обучения доступна администратору системы, когда у виртуального помощника есть обученная модель классификации и в табличной части «Параметры классификаторов Ario» заполнено поле ИД модели.
В результате опубликованная в классификаторе модель стает недействующей, и обучение классификатора начинается заново. Также в записи справочника виртуального помощника на вкладке «Дополнительно» в табличной части «Параметры классификаторов Ario» удаляются значения полей ИД модели и Действующая.
| © Компания Directum, 2025 |